
شاید عجیب به نظر برسد، اما دادهها درعینحال که ارزشمندترین داراییهای یک شرکت هستند، میتوانند مشکلسازترین دارایی شرکتها هم باشند.
شرکتی را در نظر بگیرید که خدمات آزمایش DNA ارائه میکند. خدماتی که این روزها پرطرفدار هم هست. اطلاعاتی که از آزمایش DNA به دست میآید، برای مشتریان شرکت بسیار ارزشمند است، چرا که حاوی اطلاعاتی از روابط خانوادگی و اجدادی تا ردپاهای ژنتیکی درگیر در بیماریهاست. اهمیت این اطلاعات در کنار تردیدها دربارهٔ سوگیریهای داده (data bias) نهفته در آنها، سؤالات مهمی دربارهٔ این آزمایشها به وجود میآورد. آیا این آزمایشها دقت و اعتبار کافی دارند؟ آیا میتوان به نتایج آنها اطمینان کرد؟ مشتریانی هستند که نتایج بسیار متفاوتی از شرکتهای مختلف ارائهکنندهٔ خدمات تست DNA دریافت کردهاند. گروه دیگری از افراد هم هستند که اطلاعات مورد نظرشان را در نتایج این تستها پیدا نمیکنند، آن هم بیشتر افرادی که در زمرهٔ اقلیت نژادی و قومی محسوب میشوند.
بخش عمدهای از این مشکلات، به استفادهٔ آزمایشگاهها از الگوریتمهای هوش مصنوعی (AI) در تفسیر آزمایشها مربوط میشود، تا از این طریق به کار سرعت ببخشند و اتکا به نیروی انسانی متخصص را کاهش دهند. این الگوریتمها، اگرچه سرعت بسیار بیشتری از انسانها دارند، اما تنها بر اساس مجموعه دادههایی که از گذشته جمعآوری شدهاند، کار میکنند و ممکن است دادههای پیشین نمود درستی از انواع ترکیبهای مختلف که در افراد گوناگون دیده میشود، به دست ندهند.
این نوع مشکلات، تنها گریبان شرکتهای ارائهدهندهٔ خدمات ژنتیکی را نمیگیرد. در زمینههای گوناگون، از صنایع گرفته تا تجارت، بهکارگیری هوش مصنوعی مشروط به پیداکردن راهحلهایی برای سوگیریهای داده و رفع ریسکهای احتمالی در موضوعهای اخلاقی، حقوقی و مالی، در زمینهٔ استفاده از هوش مصنوعی است.
حل مشکل سوگیری دادهها نیازمند شناخت دقیق ریشههای شکلگیری این مشکل در دادهها است. با شناخت بهتر ریشهٔ این مشکلات، شرکتها میتوانند سامانههای هوشمند را به شکلی مسئولانهتر پیادهسازی کنند و حتی عملکرد آنها را نیز بهتر سازند.
سوگیریها و چرخهٔ عمر داده (Bias and the Data Lifecycle)
در ساخت سیستمهای هوش مصنوعی از مجموعه دادهها استفاده میشود. مجموعه دادهها از تعصبها و تبعیضها نسبت به گروههای مختلف (مثلاً اقلیتهای نژادی) عاری نیستند. سوگیری داده همینجا اتفاق میافتد، یعنی هنگام ساخت سیستمهای هوشمند، براساس مجموعه دادههایی که از تعصبها و تبعیضها متأثرند. اغلب تصور میشود که این سوگیریها علیه اقلیتهای حمایت شده در یک جامعه است (قانون فدرال آمریکا از افراد در برابر تبعیض و تنفر به دلیل داشتن دین، قومیت، جنسیت، سن، معلولیت، رنگ پوست، مرام خاص، ریشههای تابعیتی، مذهب و اطلاعات ژنتیکی حمایت میکند)، اما، در واقع هر نوع سوگیری داده، به نفع یا به ضرر هر گروهی، میتواند مشکلآفرین باشد.
سوگیری، در هر گام از چرخهٔ عمر مجموعه داده (dataset lifecycle)، ممکن است به آن راه یابد: در تولید دادهها، نمونهگیری از دادهها (sampling)، جمعآوری و در نهایت در پردازش دادهها. شکلگیری سوگیری در دادهها رابطهٔ نزدیکی با ریشههای آن سوگیری در [جهان غیر دادهای] دارد.
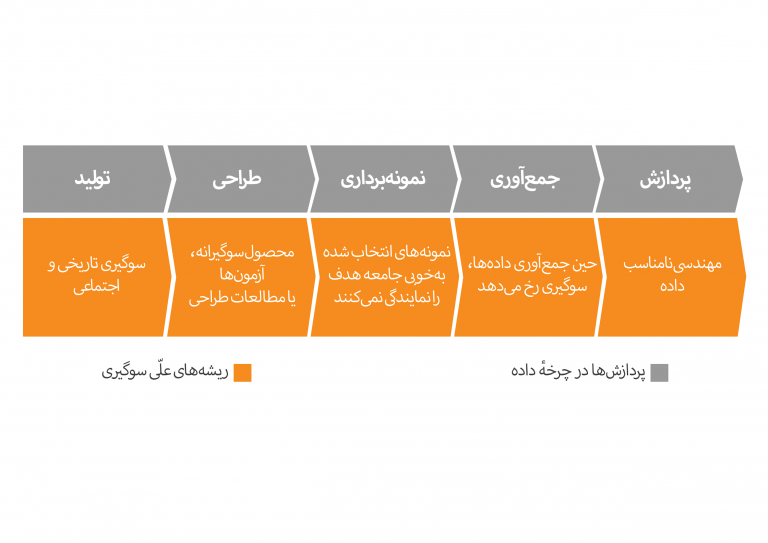
تولید دادهها: برخی سوگیریها به دلایل تاریخی و اجتماعی در جامعه وجود دارند و از این طریق وارد دادهها میشوند.
برای مثال، میتوان سوگیری دادهای را در فرایندهای استخدامی مشاهده کرد. در سال ۲۰۱۵ میلادی، ۴۲ درصد از افراد شاغل در ایالات متحده زن بودند، اما سهم زنان در مشاغل زیر گروه مهندسی، علم، فناوری و ریاضیات (STEM) تنها ۲۴ درصد بود. اگر یک شرکت با ساخت الگوریتمهای هوشمند، سعی کند از این اطلاعات تاریخی برای بهبود فرایند استخدامیاش استفاده کند، این سوگیریها از طریق دادههای تاریخی به فرایند استخدامی شرکت منتقل خواهند شد؛ بنابراین، باید در ساخت الگوریتمهای هوشمند به وجود چنین سوگیریهایی توجه کرد و هنگام ساخت سیستمهای هوشمند از برطرف شدن این سوگیریها مطمئن شد.
طراحی: روش طراحی یک سیستم مبتنی بر هوش مصنوعی یا یادگیری ماشینی میتواند باعث سوگیری در دادهها شود. اگر طراحی سیستم هوش مصنوعی (از جمله طراحی محصول، طراحی آزمونها، پژوهشها و غیره) از درون سوگیرانه باشد، دادههایی که با استفاده از نتیجهٔ آن جمعآوری میشود، نیز درگیر سوگیری خواهد بود.
برای مثال، یک شرکت پخش فیلم آنلاین را در نظر بگیرید که قصد دارد با طراحی یک پرسشنامه، سلیقهٔ مشتریانش را بشناسد. نتایج این پرسشها در طراحی یک سیستم هوش مصنوعی برای پیشنهاد دادن محتوای مورد علاقهٔ کاربران، به کار گرفته خواهد شد. ممکن است یکی از موضوعات مورد توجه برای طراحی این الگوریتمها این باشد که «آیا کودکان میتوانند با همراهی والدینشان، فیلمهای ترسناک ببیند؟» اگر این موضوع به این شکل مطرح شود که «به عقیدهٔ شما والدین دلسوز، آیا کودکان باید اجازه داشته باشند که همراه پدر و مادرشان فیلمهای ترسناک ببینند؟»، حتماً سوگیری دادهای رخ خواهد داد. اما در عوض طرح آن پرسش به این شکل که «به نظر شما آیا کودکان باید بتوانند همراه والدینشان فیلمهای ترسناک ببینند؟»، موجب سوگیری نخواهد شد.
نمونهگیری: در این مرحله اگر جمعیتی که برای نمونهگیری انتخاب میشوند، بهخوبی تمام جمعیت و موارد موردنظر را نمایندگی نکنند، سوگیری در دادهها به وجود میآید.
در سال ۱۹۶۳ میلادی، یک آژانس نظرسنجی، به نام،Literary Digest poll، در ایالات متحده پیشبینی کرد که آلفرد لاندن با کسب ۵۷ درصد از آرای انتخابات ریاستجمهوری، فرانکلین روزولت را شکست خواهد داد. نظرسنجیهای این آژانس پیشبینی میکرد که روزولت تنها ۴۳ درصد رأی خواهد آورد، اما در واقعیت روزولت با کسب ۶۲ درصد آراء، رقیبش را با فاصلهٔ زیاد شکست داد. گرچه در مطالعات نظرسنجی از جمعیت زیادی نظرخواهی شده بود، اما این آژانس، برای انتخاب نزدیک به دو و نیم میلیون نفری که در نظرسنجیها شرکت کردند، از فهرست شمارههای تلفن، اطلاعات عضویت در کلوپها و اشتراک مجلات استفاده کرده بود. در آن زمان امریکا در میانه دوران رکورد اقتصادی بزرگی بود، یعنی افرادی که نامشان در این فهرستها پیدا میشد عموماً از طبقات متوسط و بالای جامعهٔ امریکا بودند. بهعبارتدیگر، جمعیتی که برای نظرسنجی انتخاب شده بودند، همه رأی دهندگان امریکایی را نمایندگی نمیکردند و این نتیجهٔ نظرسنجی را به شدت به خطا برد.
چنین خطایی بر سیستمهای مبتنی بر هوش مصنوعی هم اثرگذار است. اگر دادههای ورودی، بهدرستی، همهٔ گوناگونیهای مختلف موجود را نمایندگی نکند، خروجی سیستم هوش مصنوعی، هرچقدر هم که حجم ورودیها بزرگ باشد، هرگز دقیق نخواهد بود.
جمعآوری داده:سوگیریها میتوانند از سه طریق در فرایند جمعآوری دادهها به آنها راه یابند:
نخست، ممکن است افرادی که مجموعه دادهها را جمعآوری و برچسبگذاری (label the dataset) میکنند، دچار سوگیریهای شخصی نسبت به آنها باشند. این مشکلی رایج در آموزش شبکههای عصبی از جمله شبکههای عصبی پیچشی (convolutional) است که در تشخیص تصاویر و چهرهها کاربرد دارند. این شبکههای عصبی در فرایند یادگیری، نیاز به حجم بسیار زیادی دادهٔ آموزشی (training set) دارند که باید از پیش برچسب خورده باشند. در واقع، این مدلها تلاش میکنند با دقت بالا، ارتباط بین دادههای آموزشی و برچسبها را کشف کنند. بسیاری از شرکتها از تصاویر و خدمات برچسبگذاری اینترنتی برای تهیهٔ مجموعه دادههای آموزشی خود استفاده میکنند تا هزینهها را کاهش داده باشند. اما اگر کسانی که این دادهها را برچسبگذاری میکنند، بر اثر آموزههای فرهنگی و اجتماعی، نسبت به موضوعاتی سوگیری داشته باشند، اثر این سوگیریها در برچسبگذاریها، به مجموعهٔ دادهها و از طریق آن به شبکههای عصبی هم منتقل خواهد شد.
دوم، دادههای پَرت (outlier) (دادههایی که به صورتی قابلتوجه با دادههای دیگر فرق دارند) و دادههای اشتباه که ممکن است به دلیل اشکالات در حسگرها یا خطاهای ماشینی دیگر ثبت شوند.
برای مثال، ممکن است مجموعهای از حسگرهای یک دستگاه خراب شده باشد و در نتیجه، ارزشهای ناهنجار (abnormal values) تولید شده باشد. بدون نظارت دقیق و تعدیل، این دست دادهها ممکن است عملکرد مدلهای هوشمند را به شدت تحت تأثیر قرار داده یا حتی بهکلی کارشان را مختل کند.
سوم،کاربران عموماً علاقهٔ زیادی به امتیاز دادن به محصولات و خدمات ندارند. این را نتفلیکس (Netflix) زمانی متوجه شد که سیستم رأیدهی پنج ستارهای را با رأی دادن خوب/بد جایگزین کرد. همین جایگزینی ساده باعث شد تعداد کاربرانی که به محصولات امتیاز میدهند ۲۰۰ درصد بیشتر شود. در واقع کاربران کمی هستند که حاضرند برای محصولات نظر بنویسند. کسانی که نظر مینویسند هم معمولاً کسانی هستند که نسبت به محصول نظری بسیار مثبت یا بسیار منفی دارند. استفاده از این نظرها باعث ورود سوگیری به نفع این دست کاربران میشود و کمتر نمایندهٔ نظر کاربران دیگری است که در میانهٔ طیف رضایت – عدم رضایت از محصول قرار گرفتهاند.
پردازش: سوگیری ممکن است هنگامیکه دادهها برای آموزش مدلها آماده میشوند، نیز به وجود بیاید.
پیش از آنکه دادهها برای آموزش مدلهای هوش مصنوعی قابلاستفاده باشند، لازم است تا پیشپردازش شوند تا کاملاً برای این کار آماده شوند. روشهای متعددی برای این کار وجود دارد: از پرکردن مقادیر خالی مانده تا نرمالسازی (normalization) (جادادن دادههایی با مقیاسهای مختلف در یک مقیاس واحد) و توکنسازی (tokenization) (تکهتکه کردن رشتهٔ متون و تقسیم آن به توکنهای کوچکتر). اما استفادهٔ بدون شناخت کافی از زمینه (context) میتواند باعث بهوجودآمدن سوگیری در دادهها شود.
برای مثال، فرض کنید در میان مجموعهای از دادههای جمعیتی که ۱۰ درصد از اطلاعات مربوط به موضوع قد افراد در آن خالی است (اندازهگیری نشده)، با استفاده از روش جایگزینی میانه، مقداری برای این مقادیر خالی پیدا میکنیم. پرکردن این جاهای خالی با یک عدد واحد (مثلاً میانهٔ (median) قد افراد)، باعث بهوجودآمدن یک سوگیری در دادهها خواهد شد. چرا که برای مثال تفاوتی که بین قد زنان و مردان هست در پرکردن مقادیر در نظر گرفته نشده است.
دادهها مادهٔ اولیهٔ سیستمهای هوش مصنوعی هستند؛ بنابراین، هرجا که در چرخهٔ دادهها سوگیریهایی وارد شود، اثر این سوگیریها به کل سیستم تسری پیدا خواهد کرد. هرچه زودتر و در مراحل ابتداییتر، این سوگیریها کشف شود، تیم توسعه یا حتی کاربران نهایی و البته مسئولان سیستم هوش مصنوعی، سادهتر و با صرف هزینهٔ کمتر، میتوانند اثر آنها را خنثی کنند.
چگونه میتوان سوگیریها دادهها را مدیریت کرد؟
گرچه ما هیچوقت نخواهیم توانست سوگیریها را از دادهها به طور کامل پاک کنیم، اما میتوانیم به شکل قابل ملاحظهای آن را کاهش دهیم. بهکارگیری این چهار رویه میتواند برای رسیدن به این هدف مفید باشد:
آموزش: آموزش سالانه (یا حتی دو بار در سال) پرسنل برای آشنایی با سوگیریهای ناخودآگاه بسیار مهم است. چنین آموزشی میتواند نیروهای مختلف شرکت را در برگیرد: از توسعهدهندگان و طراحان تا ذینفعان ارشد. توجه به تنوع در استخدام نیروی کار هم میتواند، به افزایش توجه و آگاهی از سوگیریها کمک کند.
استفاده از خدماتدهندگان «مسئول»: اگر از شرکتی برای برچسبگذاری یا جمعآوری دادهها استفاده میکنید، لازم است از حساسیت و مسئولیتپذیری آن شرکت نسبت به سوگیریهای ناخودآگاه در دادهها، اطمینان حاصل کنید.
جستجوی فعال برای کشف سوگیریها در دادهها: باید فعالانه نسبت به حساسیتها و سوگیریهایی اجتماعی وارد عمل شوید. تشویق کارکنان به مشارکت در بحث و تبادل نظر دربارهٔ انواع سوگیریها، برای کشف سوگیریهای پنهان در فرایند طراحی و پیادهسازی، مفید است. همچین، استفاده از تحلیل اکتشافی دادهها (EDA) برای تحلیل و کشف سوگیریهای پنهان در فرایندهای کاری مفید خواهد بود. اگر تحلیل اکتشافی نشان داد که سوگیریهای بالقوهای در دادهها ممکن است شکل بگیرد، دانشمندان داده باید بدون راه دادن تردید در دل خود، به این سوگیریهای بالقوه توجه کنند.
تعدیل آثار سوگیریها: اگر تحلیل اکتشافی توانست سوگیریهایی را پیدا کند، باید بهسرعت برای تعدیل اثرات سوگیری بر سیستمهای هوش مصنوعی مورداستفاده، دست به کار شد.
دستاندرکاران هوش مصنوعی، تحت هیچ شرایطی نباید اهمیت شناسایی و تعدیل اثرات سوگیری در دادهها را دستکم گیرند. هرچه سوگیریها زودتر و در مراحل ابتداییتر شناسایی شوند، پیداکردن ریشههای آنها، کنترل آثارشان و برنامهریزی برای مقابله با عواقبشان، سادهتر خواهد بود.
| منبع | medium |
| مترجم | بابک سلطانی |

![افسون زدایی از هوش مصنوعی و یادگیری ماشینی برای مدیران اجرایی [مصاحبه با تمیم صالح]](https://www.sahab.ir/wp-content/uploads/2021/09/demystifying-ai-and-machine-learning-for-executives-370x220.jpg)

دیدگاه شما