
چندی پیش، کتاب تحویل مستمر (Continuous Delivery) را با گروهی از همکاران خوانده و جلسات گپوگفتی پیرامونش داشتیم. برای من کتاب پرفایده و تاثیرگذاری بود. پیشتر هم دربارهی برخی از سرفصلهای این کتاب چیزهایی شنیده یا خوانده بودم؛ اما خواندن این کتاب کمک کرد تا ساختاری منظمتر از موضوع در ذهنم شکل گرفته و با الگوها، ضدالگوها و تکنیکهای بیشتری آشنا شوم. به خاطر دارم که کمی بعد، وقتی جلساتی در شرکت با حضور نمایندههایی از تیمهای مختلف برای تدوین مدل بلوغ کیفیت تولید نرمافزار داشتیم، یکی از کتابهایی که ارجاعات فراوانی به آن میشد و راهگشایمان بود، همین کتاب بود. بارها برای من پیش آمده که مطالب این کتاب در جریان بهبود فرآیندهای توسعهمان بکار آید از جمله وقتی میخواستیم تستهای پذیرش (acceptance) و کارایی (performance) را در سبد تستهای خودکار محصولاتمان قرار دهیم و یا این اواخر وقتی میخواستیم مقدمات فنی تجزیه یک تیم بزرگ را آغاز کنیم؛ یعنی در راه شکستن یک سیستم بزرگ به چندین زیرسیستم که هر کدام حیطهی کسب و کاری (business) مشخصی را هدف قرار دهند و هر کدام مولفهها و پایپلاین استقرار (deployment pipeline) مستقل خود را داشته باشند. اما برویم سراغ کتاب.
جهنم چه شکلی است؟
اگر بخواهم دربارهی این کتاب صحبت کنم به نظر من بیشک پردهی اول، تصویری از جهنم تیمهای توسعه است. در جهنم توسعهدهندهها، استقرار مولفههای نرمافزاری و مهیا کردن اولیهی محیط آنها به شکل دستی انجام میشود. فقط چند نفری هستند که فوتوفن این کار را میدانند؛ اما خود آنها هم با دعا و ثنا کار را پیش میبرند. به همین جهت است که از گامهای استقرار، اتفاقات بدی که در حین آن میتواند بیفتد و راهحلهایش، سند مفصلی میسازیم؛ اما گویی با هر استقرار جدید با مشکلات و ناهماهنگیهای تازهای روبرو میشویم تا همواره سطح آدرنالین خونمان بالا بماند. گاهی خطاهایی داریم که آنها را ظرف چند دقیقه برطرف کردهایم؛ اما دو سه ساعت پراضطراب برای استقرار آن باید کار کنیم!

در جهنم، خیلی از تستها را به شکل دستی انجام میدهیم؛ اما وقت نمیکنیم همهی آنها را در همهی ریلیزها دوباره چک کنیم، پس به اندکی از آنها بسنده میکنیم؛ اما محیط عملیاتی گاهوبیگاه خطاهای جدیدی برایمان رو میکند. برخی خطاهایی که سابقا درست کرده بودیم ظاهرا دوباره برگشته؛ اما چه کنیم؟ ما نمیتوانیم نبود همه خطاهای قبلی خود را در همهی ریلیزها دوباره به شکل دستی چک کنیم!
ما یک محیط آزمایشگاهی داریم. اینقدر هم سادهدل نیستیم که همه چیز را اولین بار در محیط عملیاتی آزمایش کنیم؛ اما هر از چند گاهی میبینیم که آنچه در محیط آزمایشگاهی موفق بوده، در محیط عملیاتی با خطا مواجه میشود. از واکاری ریشهی خطا در مییابیم که کانفیگ این دو محیط متفاوت است. این دو محیط با روال یکسانی کانفیگ نشده و هر کدام به شکل دستی و با ترتیب و تاریخچهای متفاوت برپا شدهاند. تنظیمات پایگاه داده، اپ سرورها و سیستمعاملها متفاوت است.
گاهی خطاهایی حیاتی گزارش شده و باید به سرعت برطرف شود؛ اما واقعا عقلمان قد نمیدهد که مشکل چیست. پس باید تغییرات اخیر را بازگردانیم (rollback) که البته اضطرابش کمتر از استقرار اولیهی این تغییرات نیست.
در جهنم معمولا تصمیماتی میگیریم که شرایط را بدتر میکند. چون تست نکردهایم، زمان ریلیز را عقب میاندازیم. چون زمان ریلیز را عقب میاندازیم کارهای جدیدی اضافه شده که آنها هم تست میخواهند. بستهای که در ریلیز قرار میگیرد، بزرگ شده و ریسکهای بیشتری را در برمیگیرد. پس فیدبکها با تاخیر میرسند؛ چه از ناحیهی تسترها و چه از ناحیهی مشتریها. فیدبکها زمانی میرسند که توسعهدهنده، دیگر آن مسئله و پیادهسازیاش را در حافظهی نزدیک خود ندارد.
تعاملات آدمها در جهنم، خود بحث دیگری است. افراد در جهنم در سیلوهای مختلفی زندگی میکنند. سیلوهای مجزای مدیران محصول، برنامهنویسها، پایگاه داده، تست، استقرار، امنیت و … . افراد هر سیلو، بر این باورند که وظایف خود را به درستی انجام دادهاند و سیلوهای دیگر را مقصر بروز مشکلات، دیرکردها و بحرانها میدانند.
شاید فکر کنید قربانی این جهنم مشتریها هستند؛ اما ترحم بر این توسعهدهندهها جایزتر از مشتریهاست. اگر بگوییم مشتریها حرارت این جهنم را حس میکنند، بیشک توسعهدهندهها خود در این جهنم میسوزند.
بهشت کجاست؟
نسخهی محصول و محیطی که میخواهیم آن نسخه را در آن مستقر کنیم را انتخاب کرده و دکمهی استقرار را میزنیم. این فرآیند استقرار در بهشت است! بهشتیها وقت خود را صرف کارهای تکراری نمیکنند. بهشتیها به شدت از کارهای کسالتبار گریزانند؛ خصوصا اینکه یک کار هم کسالت بار باشد و هم پراسترس. و به همین علت علاقمند به خودکارسازی (automation) هستند.

در اینجا، مجموعهی کاملی از تستهای خودکار داریم که هم اطمینان و هم سرعت در رسیدن به اطمینان را به ارمغان میآورند. تستهای واحد (unit)، تستهای پذیرش (acceptance) و تستهای ظرفیت (capacity)، از این دسته تستها هستند. در اینجا مفهوم تست، فراتر از صرف تست مولفههای نرمافزار است. همهی گامهای ما در فرآیند توسعه و تحویل نیز تحت سیطرهی تستها قرار دارند؛ یعنی تست اسکریپتهای build و package و deploy، تست فرآیندهای migration و rollback، تست مهیا کردن و پیکربندی (configuration) محیطهای مختلف و … . دقت کنید که وقتی صحبت از پیکربندی میکنیم، به مجموعهای وسیع از امور اشاره داریم. پیکربندی یعنی آنچه در یک محیط (عملیاتی یا تستی) بنا میشود از جمله: توپولوژی شبکه، سیستمعاملها، انواع کتابخانهها و برنامههای جانبی نصب شده بر روی سیستمها، سرویسهای زیرساختی، سرویسهای شخص ثالث (third party)، مولفههای محصول، مخازن و پایگاههای داده و خاصه تنظیمات و نسخهی دقیق هر کدام از این مولفهها.
در بهشت، نه تنها پیکربندی به شکل خودکار انجام میشود بلکه اسکریپتهای مربوط به بنا کردن یک محیط و تنظیماتی که قرار است اعمال شود، همگی شهروند درجه یک (first class citizen) هستند. آنها هم مانند کدها در مخزن کد قرار میگیرند. بازبینی میشوند و تست دارند. و چون محیطهای تست و عملیاتی با اسکریپتها و روالهای یکسانی برپا میشوند، کمتر پیش میآید که با اتفاقاتی روبرو شویم که برای اولین بار در محیط عملیاتی رو میشوند. آنچه در اینجا همواره میبینیم، تغییراتی کوچک است که به شکل خودکاری تست شده و به شکل مطمئنی تا محیط عملیاتی پیش میرود و روزانه بارها این روند تکرار میشود.
در بهشت، همه خود را مسئول رساندن موفقیتآمیز امکانات و خدمات به مشتریها دانسته و برای این کار با هم همکاری و تعامل دارند. اگر برای برآورده کردن اهداف کسب و کار لازم به تعاملات بیشتر بین برخی افراد باشد، آنها به هم نزدیکتر میشوند و گاهی تا جایی پیش میرود که مرز بین سیلوها به کلی از بین رفته و افراد خود را در تیم واحدی با ماموریت یکسانی میبینند.
مسیر ما به سمت بهشت
مقصد مشخص است؛ اما چطور این مسیر را طی کنیم؟ سوالات و چالشهای متعددی مطرح است:
ما با تستهای واحد، آشنایی زیادی داریم؛ اما انواع دیگری از تستها هم هستند. مثلا تستهای پذیرش (acceptance) که زبان و لحنی نزدیک به کاربران داشته و به شکل سیستمی در محیطی مشابه عملیات اجرا میشوند. این دسته از تستها را چگونه میتوان توسعه داد؟ چه الگوها و پرکتیسهایی برای نوشتن تستهای پذیرش وجود دارد؟ همین سوال در مورد تستهای کارایی (performance) و بار (load) و فشار (stress) هم مطرح است. این تستها را چطور میشود توسعه داد و نگهداری کرد؟ و چگونه باید آنها را در پایپلاین استقرار خود فراخوانی کرد؟ آیا میشود چکها و تستهای امنیتی را نیز به شکل خودکار و در پایپلاین استقرار انجام داد؟ برخی از این تستها و تحلیلها زمانگیر هستند. چطور میشود آنها را طوری انجام داد که بتوانیم همچنان فیدبکهای سریع و ریلیزهای متعدد و مستمر داشته باشیم؟ اگر قرار است از مزایای برخی از انواع تستهای غیرماشینی مانند تستهای کاوشگرانه (exploratory)، تستهای جمعیتی (crowd testing) و dogfooding بهره ببریم، چطور میتوانیم آن را با محیط خودکار و پرشتاب خود همراستا کنیم؟ برای استقرار تغییرات پیچیده چه راهکارها و تکنیکهایی وجود دارد؟ برای مثال تغییراتی را که با مهاجرت داده (data migration) یا حتی تغییر زیرساختها همراه است را چطور باید انجام دهیم؟ …
گاهی هم سوالات ما در جزییات و گامها نیست. مشتاقیم با تصویر کلی (big picture) ماجرا آشنا شویم و میخواهیم بدانیم چگونه میتوان این گامها را به هم متصل کرده و یک پایپلاین استقرار را سروشکل داد.
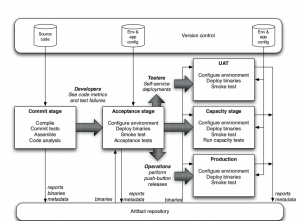
خوشبختانه این کتاب در هر دو جنبهی یادشده گفتنیهای زیادی برای ما دارد. به عنوان مثال در فصل ۵ با آناتومی پایپلاین استقرار آشنا میشویم و تصویر کلی در ذهنمان شکل میگیرد.
در مورد چالشهای دیگر نیز به فراخور در فصلهای مختلف بحث شده است. به عنوان مثال فصلهای مستقلی در مورد هر یک از مباحث تستهای پذیرش، تستهای مربوط به ویژگیهای غیرعملکردی (nonfunctional) و تحلیلهای امنیتی، مدیریت داده و تکنیکهای مربوط به مهاجرت دادهها، مدیریت زیرساختها و محیط و … در نظر گرفته شده است.
در این کتاب بسیاری از تکنیکهایی را که در ارتباط با مباحث تست، خودکارسازی و استراتژیهای استقرار و ریلیز شنیدهاید مرور خواهید کرد و شاید با موارد جدیدی نیز روبرو شوید. برای نمونه، به برخی از تکنیکهایی که در این کتاب بحث میشود و هر کدام میتواند بالقوه پاسخ یکی از چالشهای شما باشد، اشاره میکنم:
استقرار آبی-سبز (blue-green deployment) برای رسیدن به مدت پایین بودن صفر (zero downtime).
ریلیز قناری (canary release) برای کاستن از میزان ریسک ریلیز و همینطور تست کردن برخی جنبههای کارایی که در محیطهای غیرعملیاتی قابل انجام نیست.
تست A/B برای آشنایی با ترجیحات کاربران یا مقایسه نتایج عملکرد راهحلهای مختلف با هم.
فلگ زدن برای ویژگیها (feature flag) و شاخه زدن مبتنی بر انتزاع (branch by abstraction) برای اینکه بتوانیم هم به شکل مستمر کدهای جدید را در مخزن کد ادغام کنیم (continuous integration) و هم بتوانیم این را از دید مصرفکنندگان سرویس مخفی کرده و تا زمان عملیاتی شدن ویژگیهای جدید، سرویسها را به همان شکل سابق ارایه کنیم.
تکنیک چرخ ضامندار (ratcheting) برای وقتیکه میخواهیم خطاهای مربوط به تحلیلهای استاتیک را به صفر رسانده یا میزان پوشش تست را تا حد معینی افزایش دهیم؛ اما حجم بزرگی از کد جلوی روی ما قرار دارد که نمیتوانیم به یکباره این کار را انجام دهیم.
تکنیک کش کردن لاگهای رخداد و ماخذ کردن رخدادها (event sourcing) به هنگام عقبگرد (revert) در مهاجرت دادهها (data migration).
تکنیک استفاده از ماشینهای مجازی (virtual machine) برای برپا کردن سریع محیطهای تست طوریکه بتوانیم زیرساختها را با سرعت بالا بر اساس تصاویر (image) از پیش تهیه شده برپا کنیم.
…
گزیدهای از حکمتها
این کتاب ،چندان به ابزارها نمیپردازد. در برخی فصلها اشارهای گذرا به برخی ابزارهای متداول یک موضوع میکند؛ اما این صرفا از جهت آشنایی و اشاره است. تلاش اصلی کتاب، آشنا کردن مخاطب با اصول، پرکتیسها، تکنیکها و مهمتر از آن تحلیل مزایا و معایب راهکارهاست. بههمین علت است که این کتاب که در سال ۲۰۱۰ نگاشته شده، همچنان برجستهترین کتاب در حیطهی مورد بحثش به حساب میآید. دوست دارم در پایان این نوشتار دستکم به عنوان نمونه هم که شده، برخی از اصول و به تعبیر من حکمتهایی را که در این کتاب مطرح شده، ذکر کنم. برخی از این اصول به تناسب موضوع چندین بار و در فصول مختلف کتاب تکرار شدهاند:
اسکلت و بنای اصلی پایپلاین استقرار خود را از همان ابتدای پروژه شکل دهید.
مراحل پایپلاین را بر اساس ایده سریع شکست خوردن (fail fast) بنا کنید.
از شاخه اصلی کدبیس فاصله نگیرید. تغییراتی کوچک داشته باشید که به شکل مستمر در کدبیس ادغام میشوند.
همه چیز را در مخزن کد قرار دهید: کد، مستندات، اسکریپتهای تولید مولفهها و استقرار، تنظیمات محیطهای مختلف، … .
خودکارسازی را بر مستندسازی ترجیح دهید. چیزی که خودکار شده مستند، قابل ارزیابی و بازبینی، تکرار پذیر و با سرعت قابل اجراست و چون باید قابل اجرا باشد، بهروز هم هست.
انجام شده (done) به معنای منتشرشده در محیط عملیاتی (released) است و در غیر این صورت، کار به پایان نرسیده است.
هر نسخه از آرتیفکتهای باینری شما باید تنها یکبار ساخته شود. ساختن مجدد یک نسخه از آرتیفکت برای استفاده در محیطهای مختلف خطاست.
اطمینان یابید که فرآيند استقرار شما، غیرحساس به تکرار (idempotent) است.
تا جای ممکن استقرار موضوعات مختلف را همزمان نکنید. به عنوان مثال ویژگیهای جدید و مهاجرت داده را همزمان نکنید.
این بود معرفی کوتاه من از کتاب خواندنی تحویل مستمر. امیدوارم شما را به خواندن آن ترغیب کرده باشم و یا اگر آن را مطالعه کردهاید، این نوشتار یک یادآوری مسرتبخش بوده باشد.





دیدگاه شما