
استفاده از ابزارها و فریمورکهای مختلف بدون اینکه درک عمیقی از پشتصحنه وجود داشته باشد شاید برای انجام یک کار در اندازهٔ کوچک یا متوسط کافی باشد. ولی قطعا برای انجام یک کار در اندازهٔ بزرگ با وجود شاخصههایی مثل قابلیت اطمینان (Reliability) ، مقیاسپذیری (Scalable) و قابلیت نگهداری (Maintainable) کافی نیست. اینجاست که باید درک عمیقی از پشتصحنهٔ ابزارها و فریمورکها داشته باشیم تا بتوانیم ابزار مناسب را انتخاب کنیم و بدانیم در شرایط مختلف به چه شکل عمل می کنند و اصلا چه تنظیماتی باید به چه شکل انجام شود تا از ابزار انتخابی به بهترین شکل استفاده کنیم. این مسئله در دنیای پردازش دادههای حجیم با توجه به پیچیدگیهای ذاتی پردازش توزیعشده و تنوع ابزارهای موردنیاز با شدت بیشتری وجود دارد.
مهندسی داده (Data Engineering) یک عنوان شغلی نسبتا جدید است که هدفش طراحی و پیادهسازی پایپلاینهای دریافت، ذخیرهسازی، آمادهسازی و بازیابی دادهها با هدف تسهیل امکان اجرای پردازشهای تحلیلی پیچیده بر روی داده است. مطالعات متعددی در سطح بینالمللی نشان داده که جایگاه شغلی مهندس داده به لحاظ نرخ رشد و همچنین سطح پرداختها، در رتبهٔ نخست جایگاههای شغلی قرار دارد:
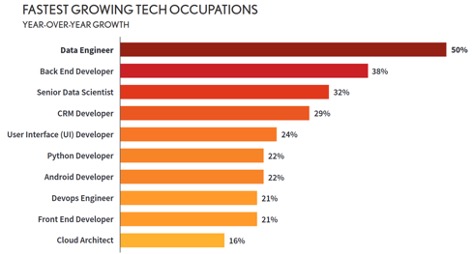
طبیعتا طراحی پایپلاینهای داده و عملا معماری محصول، متناسب با ویژگیهای مسئله متفاوت است و اولین مرحله، طراحی معماری سیستم است. در طراحی معماری سیستم باید دانش کافی در مورد انواع مدلهای پردازشی و ذخیرهسازی و بازیابی داده و همچنین شناخت درستی از نیازمندیها و ویژگیهای مسئله موردنظر وجود داشته باشد:
- حجم دادهها، نرخ ورود و تنوع آن به چه شکل است و کجا و به چه شکل باید به صورت موقت یا دائمی ذخیره شود؟
- چه تضمینی در مورد دادهها نیاز است؟ سازگاری داده (Data Consistency) تا چه حد مهم است؟ دسترسپذیری (Availability) چطور؟
- ازدسترفتن یک داده چقدر اهمیت دارد؟
- کش کردن داده نیاز است یا نه؟
- برای ذخیرهسازی از پایگاه دادههای رابطهای (Relational Database) استفاده شود یا بر پایهٔ سند (Document-Based) یا فایل سیستم توزیعی؟
- نیاز به پردازش جریانی (Stream Processing) وجود دارد یا پردازش دستهای (Batch Processing) یا هر دو؟
- و …
بر اساس این معیارها باید نوع مولفهها در معماری یک سیستم دادهای انتخاب شود.
در مرحلهٔ بعد برای پیادهسازی بخشهای مختلف متناسب با معماری طراحیشده از ابزارهای مختلفی استفاده میشود. عوامل زیادی در انتخاب ابزار برای هر بخش تاثیرگذار است. از وجود نیروی انسانی متخصص گرفته تا انطباق با نیاز ما.
مرحلهٔ بعد پیکربندی ابزار است. عموما تعداد پارامترهای قابل تنظیم ابزارهای داده خیلی زیاد است. برای استفادههای دمدستی معمولا تنظیمات پیش فرض بهخوبی کار میکند و کافی است. برای استفادهٔ حرفهای و در مقیاس بزرگ از یک ابزار، باید معماری آن را بشناسیم و از پشتصحنهٔ آن مطلع باشیم، تنظیمات اصلی را بدانیم و بر اساس صورت مسالهای که داریم پیکربندی را انجام دهیم.
با توجه به مواردی که تا اینجا گفته شده است، برای اینکه بتوانیم معماری درستی طراحی کنیم، انتخابهای درست برای نوع مولفهها در معماری داشته باشیم، ابزار درستی برای هر مولفه معماری انتخاب کنیم، ابزار را به نحو مناسب پیکربندی کنیم و در نهایت در مواجهه با مشکلات و باگها بتوانیم مشکلات را برطرف کنیم باید دید خوبی نسبت به پایههای دانشی سیستمهای دادهای توزیع شده داشته باشیم. حال که به نظر میرسد نیاز است پشتصحنه را تا حد خوبی بدانیم و عمیق شویم، این سوال مطرح می شود که از کجا شروع کنیم.
معرفی کتاب مهندسی داده از حرف تا عمل (Designing Data Intensive Applications)
کتابی که قصد داریم در این مطلب معرفی کنیم دقیقا در این جایگاه قرار دارد و قصد دارد شما را با مفاهیم و چالشها و مزایا و معایب انواع پیادهسازی بخشهای زیرساختی یک سیستم دادهای آشنا کند. عنوان کتاب طراحی برنامههای دادهمحور (Designing Data-Intensive Applications) با زیرعنوان «ایدههای اصلی پشت سیستمهای قابل اطمینان، مقیاس پذیر و با قابلیت نگهداری بالا» است. نویسندهٰ این کتاب آقای مارتین کلپمن استاد دانشگاه کمبریج انگلستان است و کتاب در سال ۲۰۱۷ منتشر شده است. این کتاب از سه بخش کلی تشکیل شده است. بخش اول کتاب به بیان مفاهیم پایهای سیستمهای داده میپردازد. در بخش دوم مباحث مرتبط با توزیعشدگی ارائه شده است. در نهایت در بخش سوم هم معماری کلی سیستمهای داده بیان شده است.

در بخش اول کتاب بعد از شرح دقیق قابلیت اطمینان، مقیاسپذیری و قابلیت نگهداری به بیان مدلهای داده و زبانهای پرسوجوی دادهها پرداخته شده است. در ادامه، بحث ذخیرهسازی و بازیابی داده با بیانی گامبهگام و با شروع از مفاهیم پایهای ذخیرهگاه داده (Data Storage) و مقایسهٔ انواع پایگاه دادهٔ رابطهای و بر پایهٔ سند، بحث را تا طراحی انبارهٔ داده (Data Warehouse) و ذخیرهسازی ستونی (Columnar Storage) پیش برده است. با خواندن این فصل عملا دید خوبی در خصوص انواع ذخیرهگاههای داده و مفاهیم پایهای آنها به دست می آید. در نهایت در فصل پایانی این بخش بحث کدگذاری (Encoding) و سریالسازی اشیا دادهای بیان شده است.
یکی از نکات خوب این کتاب این است که پس از توضیح روشهای مختلف پیادهسازی یک مفهوم مثل ذخیرهگاه داده، گریزی به ابزارهای معروف زده شده است و این نکته به درک پشتصحنه ابزارهای مرسوم کمک کرده و در انتخاب ابزار مناسب نیز به ما کمک میکند. مثلا فرض کنید در فرآیند طراحی معماری به این نتیجه رسیدهایم که به یک پایگاه داده NoSQL نیاز داریم. توجه کنید که مفاهیم مرتبط با انواع پایگاه داده و تفاوتهای اصلی آنها در بخش اول کتاب بیان شده است. در مرحلهٔ بعد باید ابزار مناسب را انتخاب کنیم. دو نمونهٔ اصلی از ذخیرهگاهها برای دادههای حجیم HBase و Cassandra است که در بخش اول کتاب و در بحث ذخیرهسازی مطرح شده است. این پایگاههای داده، دادهها را در قالب کلید-مقدار ذخیره میکنند و ذخیره و بازیابی با کلید به سرعت بالا انجام میشود. مثلا فرض کنید برای یک مسئله به این نتیجه میرسیم که باید قابلیت جستجو روی بعضی از فیلدهای مقدار داشته باشیم. طبیعتا اگر حجم داده خیلی زیاد باشد نمیتوانیم دادهها را چند بار ذخیره کنیم و هر بار یکی از فیلدها را کلید قرار دهیم. یعنی عملا بهتر است امکانی مثل اندیسگذاری (Index) روی برخی از فیلدهای مقدار داشته باشیم. در این حالت به جای گزینههایی مثل HBase میتوانیم از Cassandra که اندیس ثانویه (Secondary Index) را پشتیبانی میکند استفاده کنیم. البته توجه کنید که در حالت کلی باید مسئله را از ابعاد مختلف تحلیل و بررسی کنیم.
بخش دوم کتاب در مورد دادههای توزیعشده است. رونوشتبرداری (Replication) و چندپاره کردن (Partitioning) و انواع روشهای مرسوم و چالشهای مربوطه در فصلهای اول و دوم این بخش ارائه شده است. تقریبا میتوان گفت که رونوشتبرداری و چندپاره کردن در اغلب سیستمهای دادهای توزیعشده (از Kafka گرفته تا HBase و HDFS , …) وجود دارد و مسیر به سمت مقیاسپذیری، دسترسپذیری بالا و تحملپذیری خطا Fault-Tolerance) از این مفاهیم گذر میکند. در ادامهٔ این بخش از کتاب بحث تراکنشها مطرح شده است. اگر قصد دارید خواص ACID (Atomicity, Consistency, Isolation, Durability) پایگاه داده را عمیق درک کنید حتما این فصل را مطالعه کنید. نکتهٔ قابل توجهی که در این فصل بیان شده است این است که Isolation و Consistency و Durability سطوح مختلفی دارد و برخلاف تصور اولیه که مثلا پایگاه دادههای رابطهای مرسوم ACID را به صورت کامل پشتیبانی میکنند و پیشفرض اولیهٔ انواع پایگاه داده رابطهای است، باید به صورت دقیقتر گفت که به عنوان مثال سطوحی از Isolation را پشتیبانی میکنند و عموما قابل تنظیم است. در فصل بعدی مشکلات متداول در سیستمهای توزیعشده مثل بحث توافق و همگام شدن زمان سیستمها و غیرقابلاطمینان بودن شبکه مطرح شده است و در نهایت در فصل آخر این بخش از کتاب مسئلهٔ سازگاری و اجماع (Consensus) بیان شده است و سطوح سازگاری و همچنین چالشهایی که در رسیدن به اجماع در سیستمهای توزیع شده وجود دارد مطرح شده است.
شاید شنیده باشید که طبق تئوری CAP(Consistency, Availability, Partitioning)، در یک سیستم توزیعشده همزمان دو مورد از این موارد میتواند وجود داشته باشد. با توجه به اینکه از دوپاره شدن شبکه نمیتوان جلوگیری کرد در نتیجه یا باید سیستم به سمت سازگاری برود یا اینکه دسترسپذیری را انتخاب کنیم. به عنوان مثال ابزار HBase به سمت CP متمایل است و Cassandra به سمت AP. نکتهای که قابل توجه است این است که بدانیم وقتی ابزاری AP است یا CP به چه معنی است. مثلا AP یعنی اینکه کلا سازگاری داده را در این ابزار نداریم؟ باید بدانیم که سازگاری سطوحی دارد و قابل تنظیم است. کلا دنیا دنیای مصالحه است. باید یک چیز داده شود تا چیز دیگری به دست آید. یا حداقل باید از یک مورد کمتر بخواهیم تا از مورد دیگر بیشتر داشته باشیم. توضیح دقیق این مفاهیم در بخش دوم کتاب بیان شده است.
در نهایت در بخش سوم کتاب به بحث تجمیع سیستمهای مختلف دادهای (انواع مختلف ذخیرهسازی موقت و دائمی، پردازش دستهای و جریانی) در جهت ایجاد یک سیستم با یک معماری یکپارچه پرداخته شده است. در فصل اول از این بخش، پردازش دستهای و مدل پردازشی (Map-Reduce) مورد بحث قرار گرفته است و در ادامه در فصل دوم پردازش جریانی ارائه شده است. در نهایت در فصل آخر، آیندهٔ سیستمهای داده بیان شده و ایدههایی برای ساخت برنامههایی قابل اطمینان، مقیاس پذیر و با قابلیت نگهداری بالا مطرح شده است.
جمع بندی
کتاب معرفی شده در این مطلب برای مهندسین نرمافزار که تمایل به ورود به بحث سیستمهای توزیعشده، سیستمهای با کارایی بالا و در حالت کلی سیستمهای ذخیرهسازی و پردازش دادههای حجیم دارند حاوی مطالب بسیار آموزندهای است. این کتاب علاوه بر بیان مفاهیم بنیادین در سیستمهای دادهای به بیان انواع تصمیمهای طراحی و معماری سیستمهای زیرساختی و چالشها و مصالحههای موجود در آنها میپردازد. از طرف دیگر صحبت در مورد اینکه ابزارهای معروف در این حوزه از چه انتخابهای طراحی استفاده کردهاند به خواننده در انتخاب ابزار مناسب و پیکربندیهای مهم متناسب با نیازمندی های مسئله کمک میکند. در نهایت خواندن این کتاب را به همهٔ مهندسین نرمافزار و علاقمندان به حوزهٔ مهندسی داده توصیه میکنم.





دیدگاه شما